kafka-python VS confluent-kafka-python
最近业余时间一直在对比两个Python kafka客户端,想知道有什么具体区别,在选择kafka-python和confluent-kafka-python时有哪些依据。
环境介绍
1、文中所用kafka版本:kafka_2.13-2.6.0,为了方便对比分析,Topic中只有一个Partition。
2、kafka-python版本: 2.0.2
3、confluent-kafka-python版本: 1.7.0
4、librdkafka版本: git clone master
5、以如下一条随机生成的1.13KB的数据为例,其中point字段是通过程序插入的字段,用来标记序号,这点在做对比时起到了很大的作用。
1 | {"point":0,"_id":"61fbf5b54dfce68a0eacc54e","index":0,"guid":"76db89fa-c818-4fcb-acb2-c58e9dad7fab","isActive":true,"balance":"$1,521.30","picture":"https://tb2.bdstatic.com/tb/img/search_logo_big_v2_d84d082.png","age":34,"eyeColor":"brown","name":"Annette Gillespie","gender":"female","company":"OLYMPIX","email":"annettegillespie@olympix.com","phone":"+1 (807) 500-3327","address":"904 Sumner Place, Finderne, Colorado, 285","about":"Non qui reprehenderit do pariatur voluptate nostrud. Velit elit veniam Lorem non nulla incididunt dolore. Ad ullamco ad minim aute consequat eu tempor sunt pariatur. Ullamco magna duis magna velit Lorem ullamco. Pariatur eu sint incididunt consectetur exercitation non nisi dolor proident. Laborum non Lorem reprehenderit anim enim aute. Laborum tempor qui dolore velit occaecat amet aute ipsum reprehenderit dolore.","registered":"2021-10-24T06:02:28 -08:00","latitude":-80.560348,"longitude":95.047927,"tags":["voluptate","minim","nulla","laborum","non","cillum","laborum"],"friends":[{"id":0,"name":"Harris Hall"},{"id":1,"name":"Richmond Estes"},{"id":2,"name":"Gayle Hester"}],"greeting":"Hello, Annette Gillespie! You have 6 unread messages.","favoriteFruit":"apple"} |
kafka协议设计
在看客户端之前,我们先来了解一下kafka的协议设计,kafka自定义了基于TCP的二进制协议。kafka客户端实现时遵循协议格式即可和Kakfa进行交互。先熟悉以下知识点:
kafka的每种请求类型用数字表示:
https://kafka.apache.org/protocol#protocol_api_keys每个请求类型都有对应的请求(Request)和响应(Response),遵循特定的协议格式,每种类型的Request都包含相同结构的协议请求头(RequestHeader)和不同结构的协议请求体(RequestBody),每种类型的Response都包含相同结构的协议响应头(ResponseHeader)和不同结构的协议响应体(RequestBody):
https://kafka.apache.org/protocol#protocol_messages以朱忠华老师在《深入理解Kafka:核心设计与实践原理》书中讲到的Produce类型图示为例,我增加了标注:
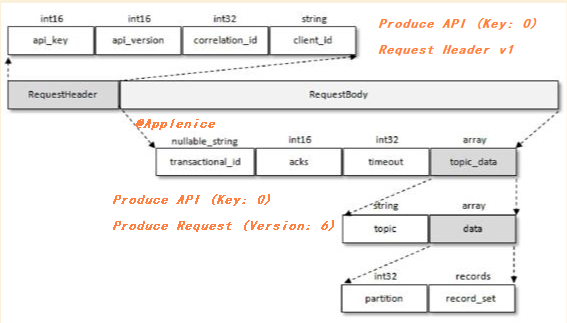
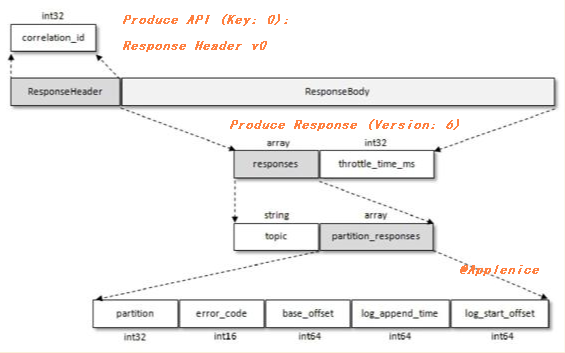
confluence Kafka APIs文档中提供了自1.1至2.8版本支持的请求类型和协议版本对比,可以快速查找协议版本的变更:
https://cwiki.apache.org/confluence/display/KAFKA/Kafka+APIs
kafka-python
介绍
kafka-Python应该是最常见的库,用起来也比较方便,通过pip安装即可:
1 | $ pip install kafka-python |
如果使用了压缩算法,比如snappy或者lz4,也是直接通过pip安装:
1 | $ pip install python-snappy |
消费配置
1 | consumer = KafkaConsumer( |
在消费时,一般会配置bootstrap_servers、group_id、enable_auto_commit、auto_offset_reset这几个基本参数,另外比较常见且重要的配置参数:
- max_poll_records: 指定在单个poll中返回的最大记录数,只控制poll返回的记录数,不影响获取(fetch),默认值500。
- fetch_max_bytes: 服务器应为获取请求返回的最大数据量,默认值52428800(50 MB)。
- max_partition_fetch_bytes: 服务器将返回的每个分区的最大数据量,默认值1048576(1M)。注意这里限制的是每个分区,客户端可以消耗的最大内存量是max.partition.fetch.bytes * num_partitions,其中num_partitions是消费者当前正在获取的分区总数。
关于fetch_max_bytes和max_partition_fetch_bytes的限制可以查看 KIP-74: Add Fetch Response Size Limit in Bytes
场景测试
接下来我们看一个常见应用场景: 假设consumer除基本参数配置外,配置max_poll_records为5000,希望每次对5000条数据进行处理。但因为max_partition_fetch_bytes默认是1M,按示例文本大小,单个poll中返回的最大记录数小于5000,仅有701条,达不到预期。那么通过修改max_partition_fetch_bytes参数,比如20971520(20M),能够得到期望的5000条数据。
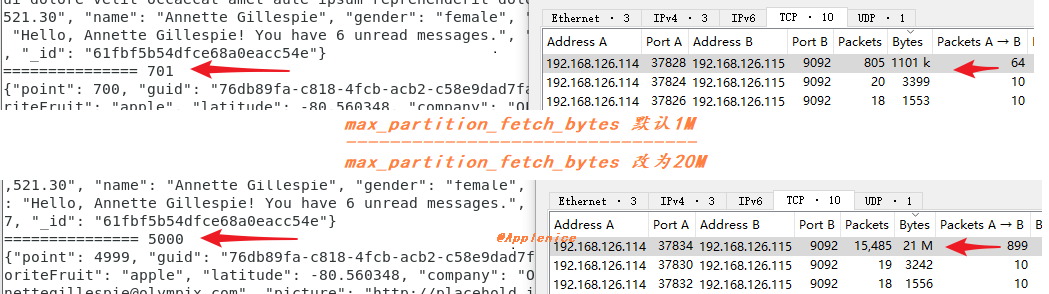
通过图上抓包捕获的数据包大小对比也可以看出限制,但这里有个细节,1.13KB * 5000是小于20M的,为什么捕获数据包大小是21M?我们来分析下数据包,之前提过我打点的point字段从0开始,通过Wireshark的Follow TCP或者Wireshark解码的Payload,可以看到consumer程序消费的数据从0开始,Fetch Response返回的数据到了point 16021,远大于设定的5000条。
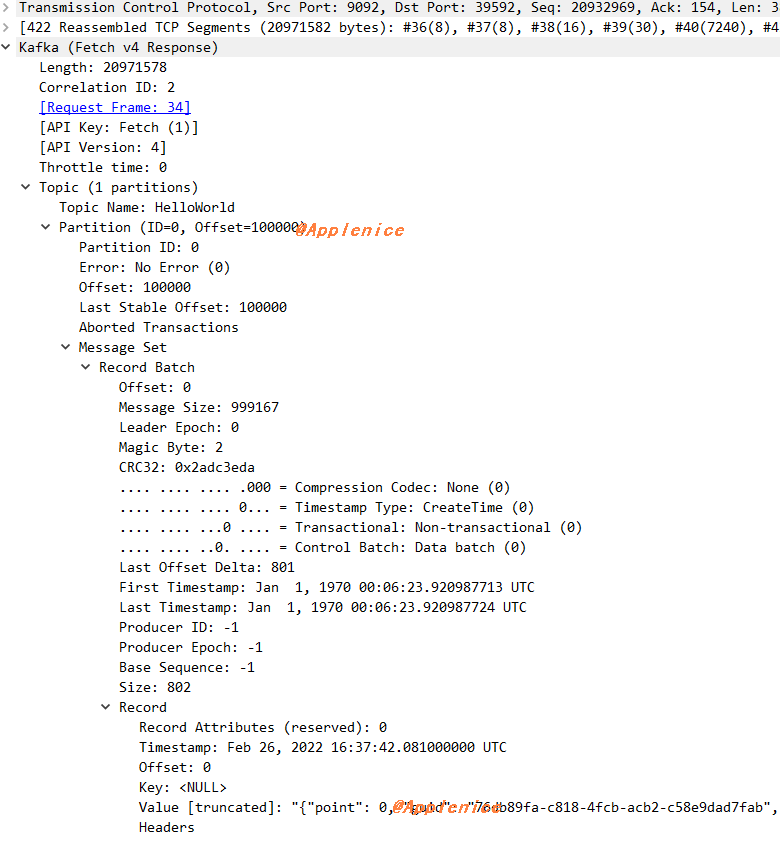
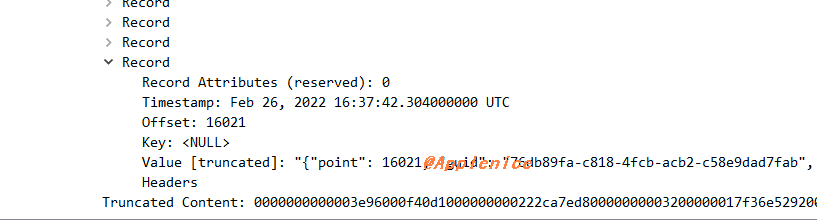
由此也能证明,max_poll_records配置只控制poll返回的记录数。
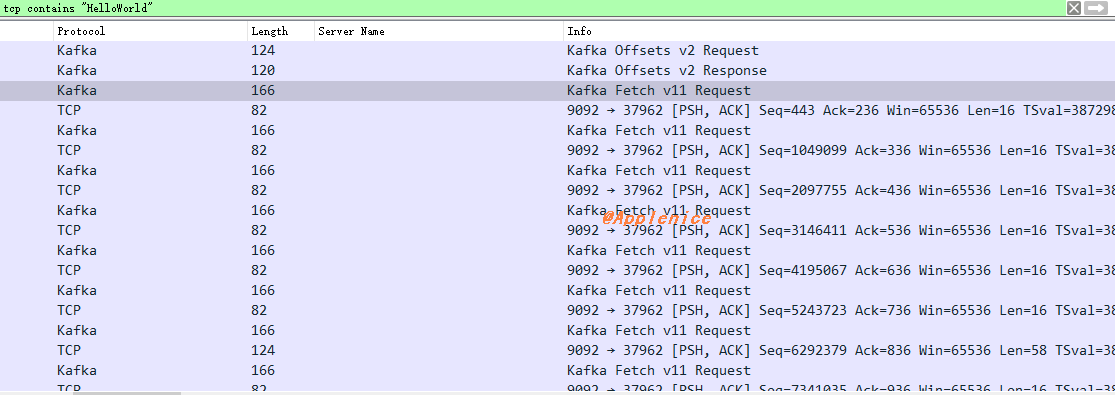
同时,在Wireshark中通过tcp contains "HelloWorld"(其中HelloWorld是我设置的Topic名称),可以看到只有一个Fetch Request:

另外,将max_partition_fetch_bytes分别设置10M和20M进行消费时,通过监控看到的流量图如下:

confluent-kafka-python
介绍
由Confluent公司支持,提供预编译版本(不包含SASL Kerberos/GSSAPI,如使用需要librdkafka的支持)。具体安装方法见可以参考:
API差异
confluent-kafka-python使用时同kafka-python一样需要配置基本参数,不过字段名格式有区别,间隔符号使用“.”:
1 | c = Consumer({ |
与kafka-python相比,confluent-kafka-python的消费API有一些差别,比如在kafka-python的Consumer通过poll方法获取消息:
1 | poll(timeout_ms=0, max_records=None, update_offsets=True) |
在confluent-kafka-python的Consumer中poll方法每次只返回一条:
1 | poll([timeout=None]) |
如果想得到相同效果,需要使用consume方法:
1 | consume([num_messages=1][, timeout=-1]) |
在confluent-kafka-python中的文档中提到,其支持的配置值由底层librdkafka C库决定,完整的配置属性需要查阅librdkafka的文档:
https://github.com/edenhill/librdkafka/blob/master/CONFIGURATION.md
在其中可以找到fetch.max.bytes和max.partition.fetch.bytes的配置,与kafka-python的默认值相同:
1 | | 区间 | 默认值 | 重要性 | |
场景测试
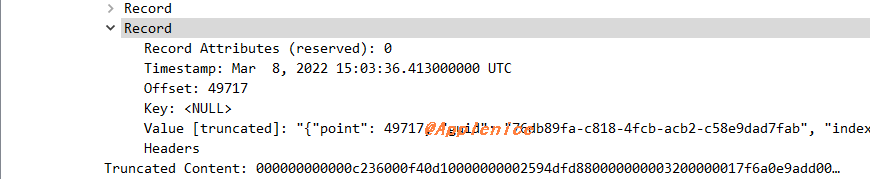
以上述kafka-python的场景为例,用confluent-kafka-python配置基本参数进行测试,一次性就得到了5000条数据,捕获的数据包大小达到了66M,但是max.partition.fetch.bytes明明默认1M,这是为什么呢?这里仍通过数据包分析,可以看到发出了多个Fetch Request,在对应的最后一个Fetch Response返回的数据可以看到point 49717。

协议版本
可能细心的同学已经发现了,抓包中能看到kafka-python和confluent-kafka-python触发了相同请求类型,但是版本并不一样。比如kafka-python的Fetch Request版本是V4,而confluent-kafka-python的Fetch Request版本是V11,差距很明显。那还有哪些不同点呢?
请求过程
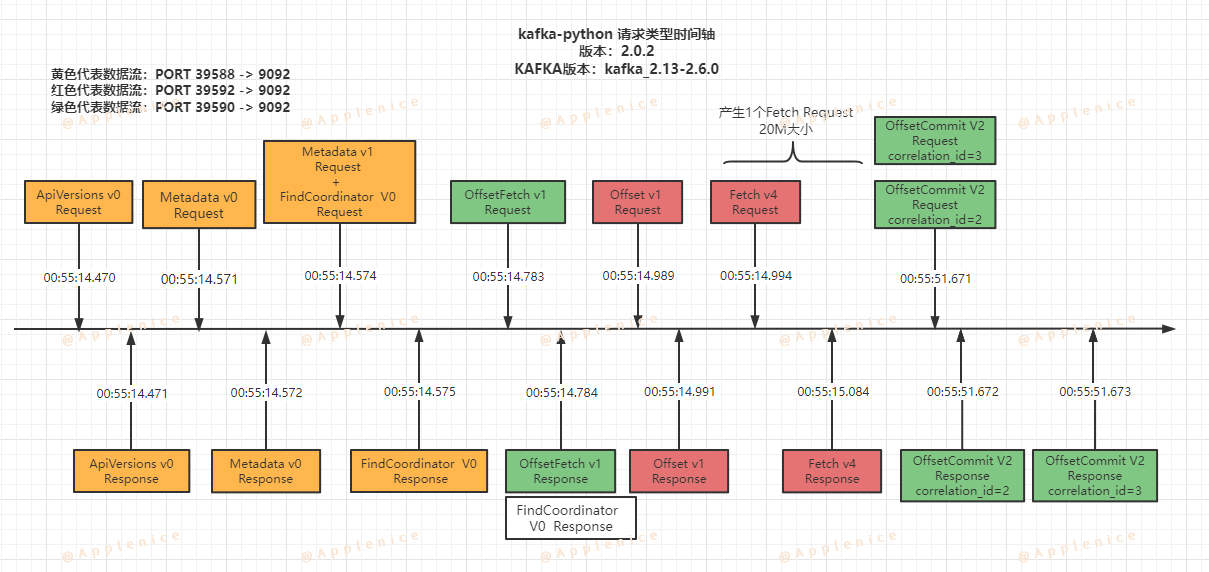
我们先按时间顺序将两种客户端触发请求的过程画出来:
1、kafka-python
2、confluent-kafka-python
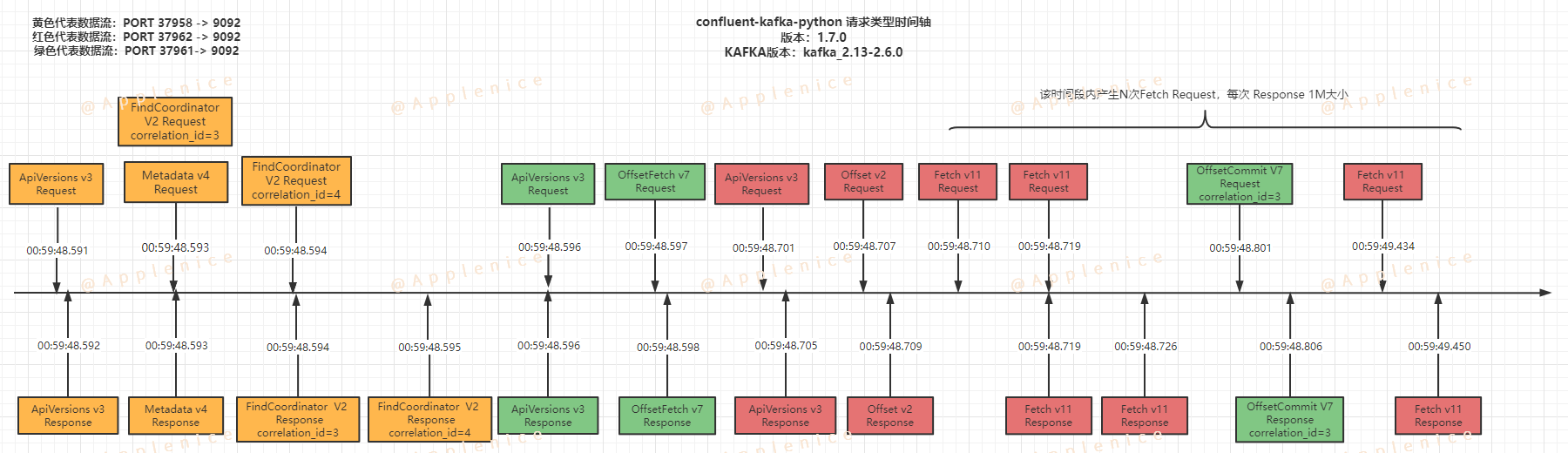
从上面两张图可以看出,两种客户端的差异点:
- 触发相同类型请求,但版本号不同
- 虽然都是三条数据流,但confluent-kafka-python在每条数据流最开始都发起了ApiVersions请求
- Metedata、FindCoordinator、OffsetCommit请求类型的处理上略有不同
- Fetch阶段的处理不同,kafka-python仅有一个Fetch请求持续接收数据到max_partition_fetch_bytes大小限制,而confluent-kafka-python发起N个Fetch请求,每次获取1M数据,直到OffsetCommit提交完毕后结束
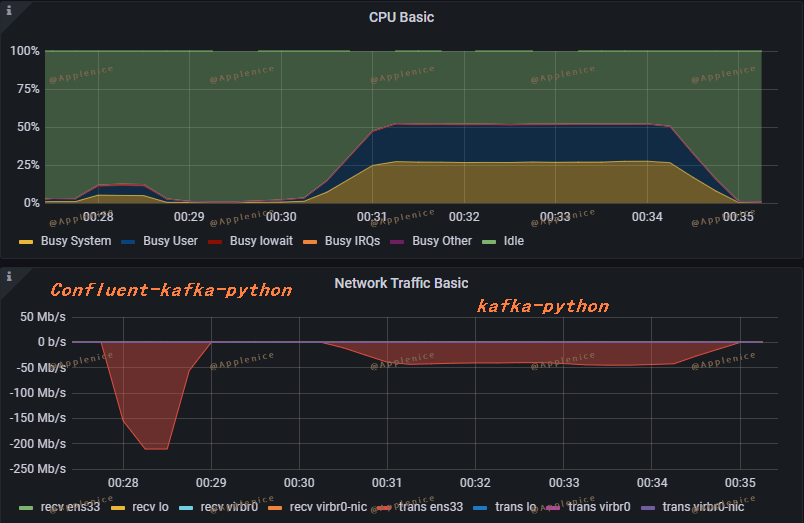
监控指标
接下来看下两种客户端在生产、消费50W条示例数据时(max.partition.fetch.bytes均为默认值1M),从监控面板上看到的情况:
1、Producer
2、Consumer
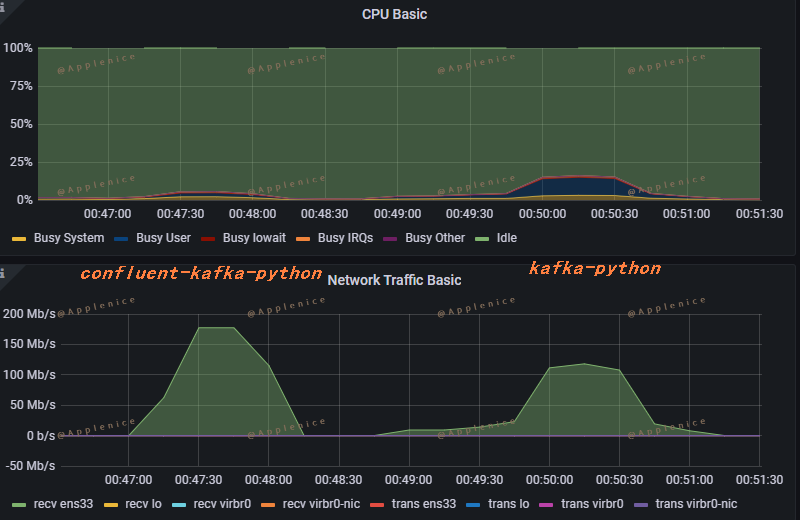
可以看出confluent-kafka-python的资源利用是明显优于kafka-python的。
ApiVersions
接下来,我们看看两种客户端是如何判断请求类型的版本号的,还是以Fetch为例:
kafka-python
在Consumer中并没有配置api_version版本,会进行自动探测,在文档中有写明:
1 | api_version (tuple): Specify which Kafka API version to use. If set to |
那么从KafkaConsumer入手,跟踪函数调用,这里只贴关键部分的代码:
1 | # 文件路径: kafka/consumer/group.py |
进入到KafkaClient后实际是去调用的conn.check_version():
1 | # 文件路径: kafka/client_async.py |
conn.check_version将ApiVersions请求类型的Response信息与test_cases进行对比,找到最匹配的版本
1 | # 文件路径: kafka/conn.py |
通过Debug可以知道,api_version是(2, 5, 0),实际的kafka版本是2.6.0,也就是说kafka-python-2.0.2客户端还没有适配2.6.0及以上的新版本带来的新特性,不过在Github上可以看到master上已经添加了对2.6.0的支持,但目前还没有release版本。
1 | test_cases = [ |
接下来我们定位下kafka-python怎么确定Fetch请求类型的版本,从consumer.poll()入手,跟踪函数调用,这里只贴函数调用路径,感兴趣的同学可以自行Debug或者查看源码:
1 | # 文件路径: kafka/consumer/group.py |
在_create_fetch_requests可以看到如下几行:
1 | if self.config['api_version'] >= (0, 11, 0): |
到这里就清楚kafka-python如何确定api_version和请求类型版本了。另外,在kafka-python中关于api_version会有部分定义默认版本,在DEFAULT_CONFIG中,比如:
1 | # consumer/fetcher.py、conn.py、sender.py |
confluent-kafka-python
confluent-kafka-python也是通过版本探测的方式来看客户端可以使用哪些特性。查看configuration文档可以看到如下配置和解释:
1 | api.version.request | * | true, false | true | high | Request broker's supported API versions to adjust functionality to available protocol features. If set to false, or the ApiVersionRequest fails, the fallback version `broker.version.fallback` will be used. **NOTE**: Depends on broker version >=0.10.0. If the request is not supported by (an older) broker the `broker.version.fallback` fallback is used. <br>*Type: boolean* |
那么同样也看下librdkafka的源码中如何判断版本,项目我导入进Source Insight中了,通过Search我们可以很快找到librdkafka在一些版本上的处理。在上面通过时间轴可以看到confluent-kafka-python的三个连接开始都是ApiVersion类型,在librdkafka中ApiVersionRequest在调用时直接传参了-1,默认按最高版本处理。
1 | rd_kafka_ApiVersionRequest( |
再来看Metadata类型,tests/0035-api_version.c测试用例调用了rd_kafka_metadata,其调用了rd_kafka_MetadataRequest:
1 | rd_kafka_resp_err_t rd_kafka_MetadataRequest(rd_kafka_broker_t *rkb, |
可以看到在发起请求前会通过rd_kafka_broker_ApiVersion_supported对协议特性进行检查来决定协议版本:
1 | # 文件名称:rdkafka_broker.c |
同理,我们可以找到对Fetch类型的版本判断:
1 | ApiVersion = rd_kafka_broker_ApiVersion_supported(rkb, RD_KAFKAP_Fetch, |
在分析过程中还有一个比较重要的地方,上面提了broker.version.fallback默认配置是0.10.0,在rd_kafka_new函数中:
1 | rd_kafka_t *rd_kafka_new(rd_kafka_type_t type, |
根据broker.version.fallback的值由rd_kafka_ApiVersion_is_queryable来决定api.version.request是否开启。
1 | /** |
可以看到rd_kafka_get_legacy_ApiVersions对broker_version版本匹配后返回是否支持。
1 | /** |
这一点上可以看出confluent-kafka-python和kafka-python都根据kafka版本做了校验。
总结
暂时就对比了这些东西,这篇文章应该是我写过最耗时的一篇,最开始只是想抓包看下流量层面的东西,发现抓包数据和文本大小对不上,加了point字段后发现疑惑点太多,就一点点找资料看代码找原因了。简单总结一下吧:
1、kafka-python的安装、操作确实简单,开箱即用,confluent-kafka-python如果需要支持Kerberos认证等会多几个步骤;
2、如果数据量比较大,又要求性能,confluent-kafka-python是最佳的选择;
3、因为confluent-kafka-python是基于librdkafka实现,在kafka协议版本实现上要高于kafka-python,如果需要使用新特性,可以优先考虑confluent-kafka-python,librdkafka支持的请求类型可以查看:https://github.com/edenhill/librdkafka/blob/master/src/rdkafka_protocol.h
4、因为API差异的存在,两种客户端在做切换时要注意代码的修改
5、类似max.partition.fetch.bytes等参数的搭配需要根据实际应用情况进行调整,找到最适合的组合
参考
1、https://kafka.apache.org/protocol#protocol_api_keys
2、https://kafka.apache.org/protocol#protocol_messages
3、https://cwiki.apache.org/confluence/display/KAFKA/Kafka+APIs
4、https://kafka-python.readthedocs.io/en/master/install.html
5、https://stackoverflow.com/questions/64820424/kafka-consumer-which-takes-effect-max-poll-records-or-max-partition-fetch-byte
6、https://cwiki.apache.org/confluence/display/KAFKA/KIP-74%3A+Add+Fetch+Response+Size+Limit+in+Bytes
7、https://github.com/edenhill/librdkafka
8、https://github.com/dpkp/kafka-python