Kafka索引的二分查找算法
一起看看页缓存与Kafka改进的二分查找算法吧,嘿嘿😉
在看Kafka的二分查找算法之前,我们先了解下两个概念:
页缓存
在《UnderStanding The Linux Kernel》一书中,关于Page Cache的描述如下:
The page cache is the main disk cache used by the Linux kernel. In most cases, the kernel refers to the page cache when reading from or writing to disk. New pages are added to the page cache to satisfy User Mode processes’s read requests. If the page is not already in the cache, a new entry is added to the cache and filled with the data read from the disk. If there is enough free memory, the page is kept in the cache for an indefinite period of time and can then be reused by other processes without accessing the disk.
Similarly, before writing a page of data to a block device, the kernel verifies whether the corresponding page is already included in the cache; if not, a new entry is added to the cache and filled with the data to be written on disk. The I/O data transfer does not start immediately: the disk update is delayed for a few seconds, thus giving a chance to the processes to further modify the data to be written (in other words, the kernel implements deferred write operations).
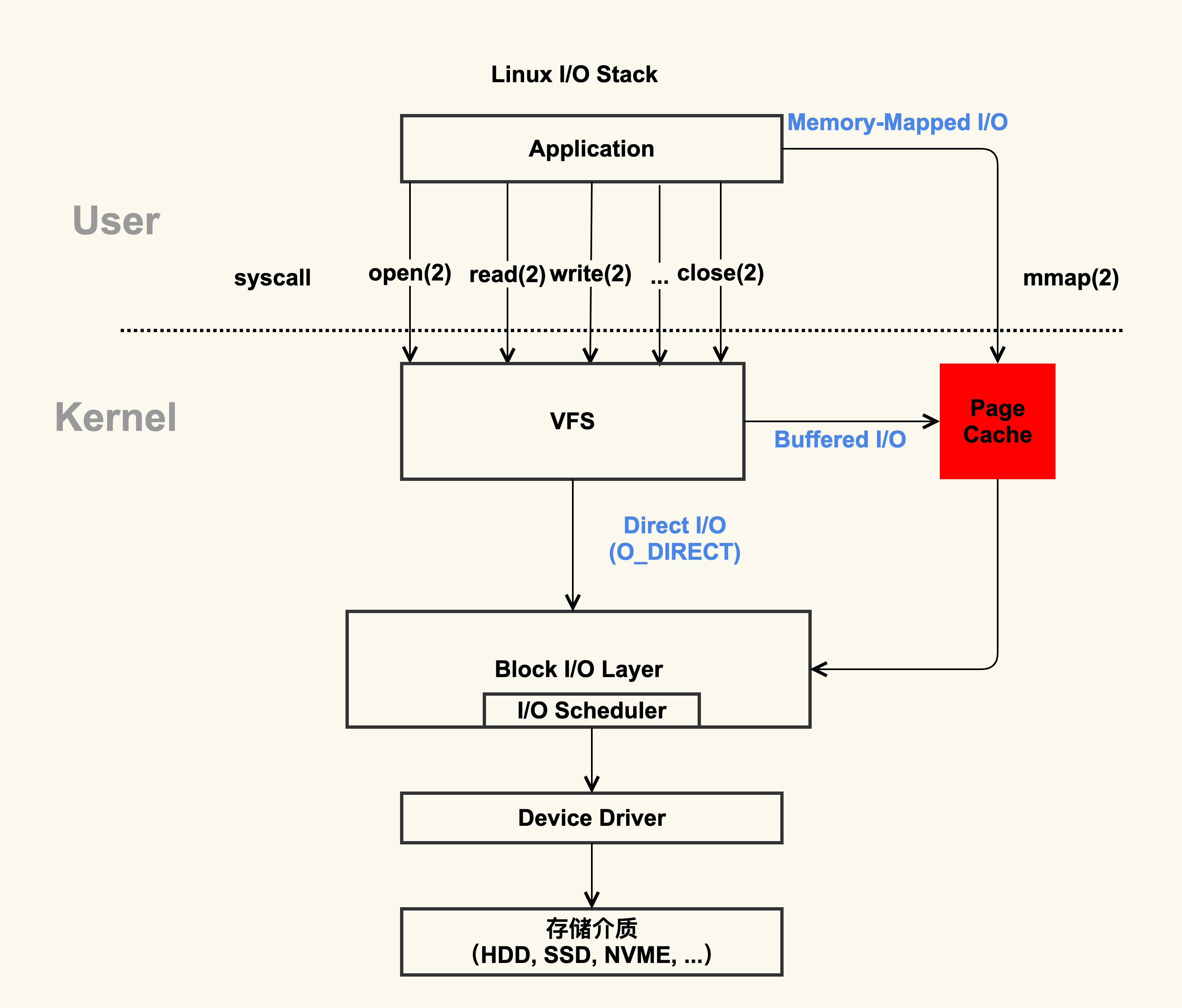
根据描述和上图可以看出,标准I/O和内存映射会先把数据写入到Page Cache,这样做会通过减少I/O次数来提升应用的I/O速度。大多数操作系统使用页缓存来实现内存映射,目前几乎所有的操作系统都使用LRU(Least Recently Used)或者类型LRU的机制来管理页缓存。
查看文件占用Page Cache情况
1、安装vmtouch,其是用于了解和控制UNIX和类似UNIX系统的文件系统缓存的工具:
1 | sudo apt install vmtouch |
2、生成内容随机的1G文件:
1 | dd if=/dev/urandom of=randomFile bs=1M count=1000 |
3、清空Page Cache,先通过sync将脏页同步到磁盘再drop cache:
1 | sync && echo 3 > /proc/sys/vm/drop_caches |
4、观察状态:
1)初始文件:
1 | ls -lrt randomFile |
2)vmtouch第一次观察
1 | vmtouch randomFile |
3)新开一个终端,用vim打开randomFile:
4)持续vmtouch观察,Resident Pages值会动态变化:
1 | watch -n 1 vmtouch randomFile |
缺页中断
Linux的缺页中断(Page Fault)异常处理须分清以下两种情况:
- 由编程错误所引起的异常;
- 由引用属于进程地址空间但还尚未分配物理页框的页所引起的异常;
通常情况下,用于处理此中断的程序是操作系统的一部分。如果操作系统判断此次访问是有效的,那么操作系统会尝试将相关的分页从硬盘上的虚拟内存文件中调入内存。而如果访问是不被允许的,那么操作系统通常会结束相关的进程。
接下来,一起看看Kafka的二分查找实现:
索引类
Kafka源码中,跟索引相关的源码文件有5个,位于core包的/src/main/scala/kafka/log目录下。这里我们只看AbstractIndex.scala,定义了最顶层的抽象类,封装了所有索引类型的公共操作。
早期版本
通过Github或者Git拉取代码后查看早期2016年时的代码,可以看出这里用了标准二分查找算法。
1 | /** |
改进版本
早期的Kafka在查询索引的时候应用标准二分查找算法,未考虑到缓存的问题,因此很可能会导致一些不必要的缺页中断。kafka线程会阻塞,等待对应的索引项从物理磁盘中读出并放入到页缓存中。
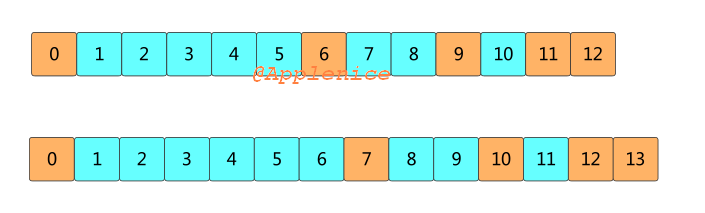
比如某个索引占用了页缓存13个页,如果待查找的位移值在最后一个页Page 12上,标准二分查找会依次读取0,6,9,11,12。通常Page 12会不断被填充新的索引项,如果索引查询都来自ISR副本或者lag很小的消费者,那么查询大多集中在Page 12上,Page 0,6,9,11,12会经常被源码访问。当Page 12被写满,最新的索引项会保存在Page 13中,这时标准二分查找会读取0,7,10,12,13。但Page 7、10很久没被访问过,大概率不在页缓存中,此时会发生缺页中断。
查看AbstractIndex.scala的变更历史:
1、早期的二分查找函数为indexSlotFor,代码已放在上面
2、Implement transaction index for KIP-98中变更为indexSlotRangeFor,未有大的变化
3、Lookup indices may cause unnecessary page fault中提出了缺页中断的问题,indexSlotRangeFor产生了比较大的变化
4、MINOR: More efficient midpoint calc for AbstractIndex进行了优化,但产生了infinite loop的BUG
5、HOTFIX: Fix infinite loop in AbstractIndex.indexSlotRangeFor修复了infinite loop的BUG
当前indexSlotRangeFor函数代码片段:
1 | /** |
改进后的算法对缓存友好,代码将所有索引项分成了两个部分:
- Warm Area热区
- Cold Area冷区
分别在这两个区域内执行二分查找算法。查询最热那部分数据所遍历的Page永远是固定的,因此大概率在页缓存中,从而避免无意义的缺页中断。有效地提升页缓存的使用率,在整理上降低物理I/O,缓解系统负载瓶颈。
其中_warmEntries起到分割线的作用,目前固定为8192字节处:
1 | protected def _warmEntries: Int = 8192 / entrySize |
源码注释中给出了为什么设置为8192字节的原因:
1 | We set N (_warmEntries) to 8192, because |
到此,关于Kafka索引中的二分查找算法就学习完毕了。
Kafka PR类型
Kafka的PR类型分为两类: 普通PR、MINOR PR。MINOR PR属于改动微不足道的PR,比如某个单词拼写错误,或者变量命名不清晰这类问题提的PR,命名时以”MINOR:”开头。普通PR在提交之前,需要保证要修复的问题在Jira中存在对应的ticket,并最好确保Jira的Assignee是自己。
参考
1.https://cwiki.apache.org/confluence/display/KAFKA/Index
2.https://issues.apache.org/jira/browse/KAFKA-6432
3.https://issues.apache.org/jira/browse/KAFKA-5121
4.https://github.com/apache/kafka/pull/5378
5.https://github.com/apache/kafka/pull/7702
6.https://issues.apache.org/jira/browse/KAFKA
7.http://kafka.apache.org/contributing
8.https://cwiki.apache.org/confluence/display/KAFKA/KIP-98+-+Exactly+Once+Delivery+and+Transactional+Messaging
9.https://en.wikipedia.org/wiki/Page_cache
10.https://www.oreilly.com/library/view/understanding-the-linux/0596005652/ch15s01.html
11.《Kafka核心源码解读》