Kafka日志管理
继续学习下Kafka的日志管理,要学不动了🤣
服务端配置
先看看Kafka的server.properties文件中关于日志刷新策略和日志保留策略的部分:
1 | log.flush.interval.messages=10000 |
追加的消息立即写到文件系统的操作系统页面缓存中,有以上两种策略会刷新磁盘,超过10000条消息或经过1秒就调用一次fsync,将页面缓存的数据刷写到磁盘中。
日志清理支持两种策略:
- 时间策略:
log.retention.hours=168,表示只会保存168小时 - 大小策略:
log.retention.bytes=1073741824,超过这个大小,多余的数据会被删除,保证日志不能太大
log.retention.check.interval.ms=300000表示每五分钟检查是否有删除的日志
在启动Kakfa之后,可以在logs/kafkaServer.out文件中看到KafkaConfig values,会打印出一些默认的配置,比如日志清理和日志刷新部分,基本上每个配置的含义都可以在Confluent的文档中查到,至于要说为什么Kafka的配置参数含义去看Confluent的文档,可以看看InfoQ的文章Confluent:在 Kafka 上飞驰的数据交换者
言归正传,看看下面这些配置和他们的含义:
1 | log.cleaner.backoff.ms = 15000 #进行日志是否清理检查的时间间隔 |
日志清理
日志清理支持两种策略:
- 删除(delete),也就默认清理策略,超过日志的阈值时,直接物理删除整个日志分段;
- 压缩(compact),不直接删除日志分段,而是采用合并压缩的方式。
删除日志的实现思路: 将当前最新的日志大小减去下一个即将删除的日志分段大小,如果结果超过阈值,则允许删除下一个日志分段;如果小于阈值,则不会删除下一个日志分段。如图:
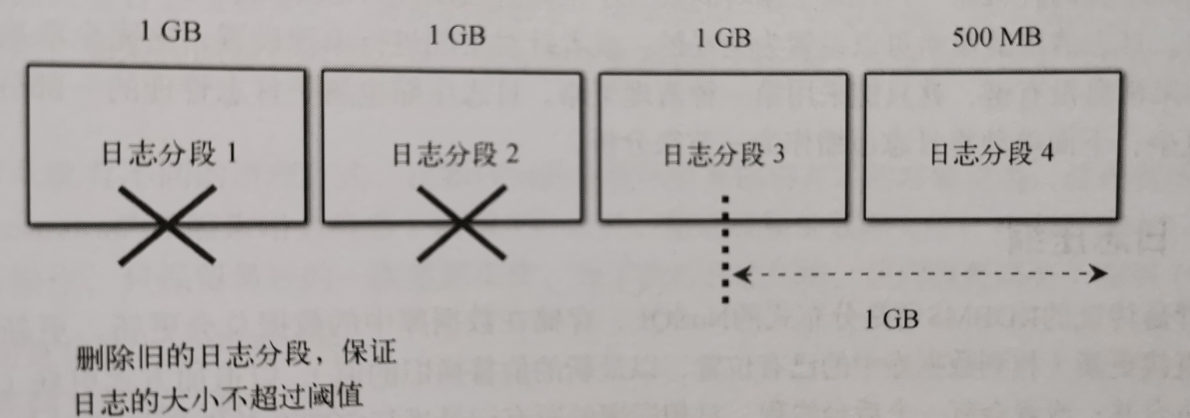
相关代码在这里:
1 | private def deleteRetentionSizeBreachedSegments(): Int = { |
删除日志分段是一个异步操作,在执行异步操作前,会从Log对象中维护日志分段的跳跃表中移除待删除的日志分段,以保证没有线程对这些日志分段进行读取操作,并将日志分段的所有文件添加上.deleted后缀,最后才由名为delete-file的延迟任务来删除.deleted后缀的日志分段文件。
相关代码:
1 | private def deleteSegmentFiles(segments: Iterable[LogSegment], asyncDelete: Boolean): Unit = { |
日志压缩
Kafka的消息由键值组成,日志压缩时,对于有相同key的不同value值,只保留最后一个版本,如图所示:
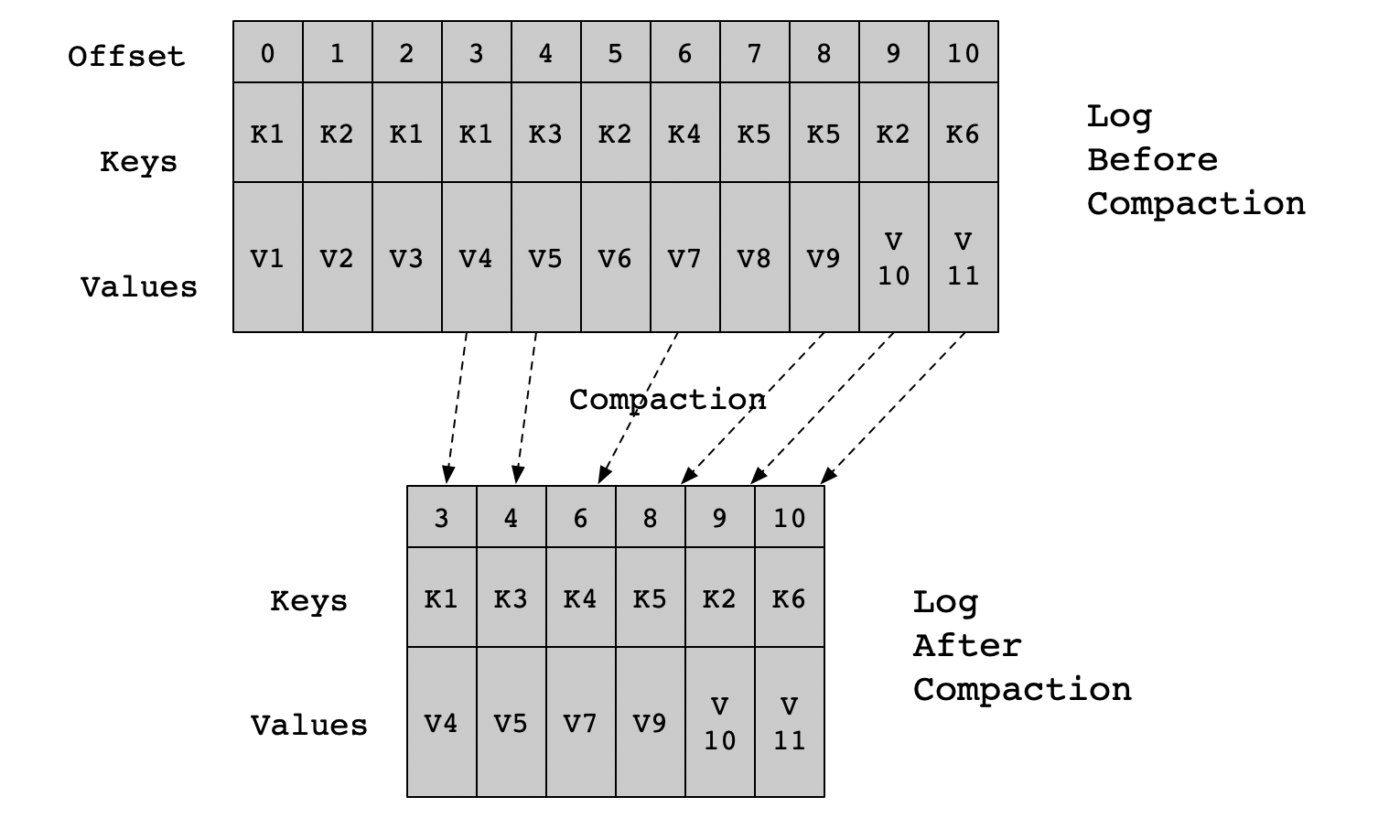
键为K1出现了三次,偏移量分别为[0, 2, 3],只会保留偏移量等于3的记录。
日志压缩的具体实现建议看书,《Kafka技术内幕》和《深入理解Kafka》中讲的都比较详细,这里只做一些简单的笔记好了。
1、清理点
执行日志压缩需要解决的两个问题:
- 如何选择参与合并的文件
除了当前活动的日志分段,Kafka的日志压缩会选择其他所有的日志分段参与和being操作。之所以排除活动的日志分段是为了不影响写操作,因为消息总是追加到活动的日志分段末尾。 - 选择到文件后,如何进行压缩
日志压缩会将所有旧日志分段的消息复制到新的日志分段上。为了降低复制过程产生的内存开销,Kafka会在日志开始压缩操作之前,将日志按照”清理点”(CleanerPoint)分成日志尾部和头部。
2、删除点(墓碑消息)
Kafka提供了墓碑消息(tombstone)的概念,如果一条消息的key不为null,但其value为null,那么此消息就是墓碑消息。
日志清理线程在发现墓碑消息时会先进行常规的清理,并保留墓碑消息一段时间。日志分段保留墓碑消息的条件是当前墓碑消息所在日志分段的最近修改时间lastModifiedTime大于deleteHorizonMs。
deleteHorizonMs计算方式:
从0到日志头部起始位置前的最后一个日志分段,它的最近修改时间 - 保留阈值(log.cleaner.delete.retention.ms)
参考
1、https://docs.confluent.io/current/installation/configuration/broker-configs.html
2、《Kafka技术内幕》
3、《深入理解Kafka: 核心设计与实践原理》