Kafka的日志存储(一)
用了Kafka一段时间了,想深入了解一下Kafka的存储是怎么回事,比如存储的格式是什么样的,那么就开始吧😆~
文件目录
我们都知道Kafka的各个Topic之间互不影响,每个Topic又可以分为一个或者多个Partition,在生产消息时会根据分区规则被追加到指定的Partition中,Partition中的每条消息都会被分配一个唯一的序列号。
假设以单节点的Kafka做示例,创建一个名为Hello-Kafka具有双Partition的Topic:
1 | bin/kafka-topics.sh --create --bootstrap-server 0.0.0.0:9092 --replication-factor 1 --partitions 2 --topic Hello-Kafka |
每个分区对应一个Log对象,在物理磁盘上对应一个子目录,可以在log.dirs中看到Hello-Kafka-0和Hello-Kafka-1的文件夹,进入到里面查看可以看到四个文件:
1 | $ ls -alrt |
为了防止日志过大,Kafka中引入了LogSegment(日志分段)的概念,将日志拆分为很多小文件,每个LogSegment的日志文件都有对应的两个索引文件: 偏移量索引文件和时间戳索引文件,如下图:
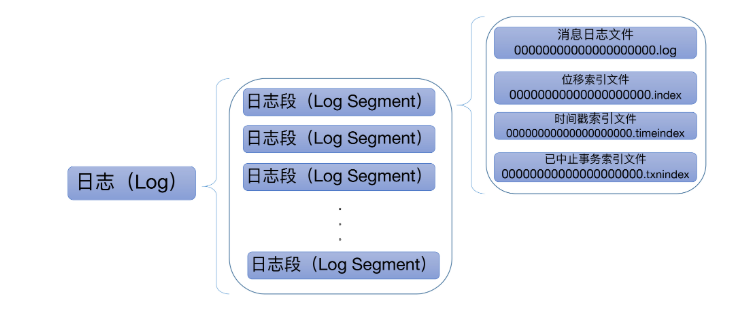
每个LogSegment都有一个基准偏移量baseOffset,用于表示当前LogSegment中的第一条消息的offset,偏移量为64位的长整型数,日志文件、两个索引文件都根据baseOffset命令,名称固定为20位数字,比如上面我们新创建的Topic,第一个LogSegment的baseOffset为0,对应的日志文件即为00000000000000000000.log。如果写入一定量的消息后,那么就又会有变化。
文件类型
那么除了上面看到的几种和检查点文件以外,在Kafka中到底有多少种文件类型呢?这可以在kafka的源码中找到答案,在log.scala文件中可以找到如下内容:
1 | /** |
其中.snapshot是Kafka为幂等型或事务型Producer所做的快照文件;.deleted是删除日志分段操作创建的文件。目前删除日志分段文件是异步操作,Broker端把日志分段文件从.log后缀修改为.deleted后缀;.cleaned和.swap都是Compaction操作的产物;-delete应用于文件夹的,当删除一个主题的时候,主题的分区文件夹会被加上这个后缀;-future用于变更主题分区文件夹地址的。
日志索引
首先了解下什么是稀疏索引(Sparse Index)?
在Simon Fraser University的课程CMPT 354 Database Systems and Structures中有描述:
1 | Sparse Index: |
Kafka中的索引文档采用稀疏索引的方式构造消息的索引,并不保证每个消息都在索引文件中有对应的索引项。当写入一定量时(由broker端参数log.index.interval.bytes指定,默认4096,即4KB)的消息时,偏移量索引和时间戳索引分别增加一个偏移量索引项和时间戳索引项,通过调整log.index.interval.bytes的值,可以增加或缩小索引项的密度。当需要查询指定偏移量或指定时间戳时,使用二分查找法来快速定位偏移量的位置。
日志分段文件进行切分(其对应的索引文件也要进行切分)的条件:
log.segment.bytes: 超过默认配置1GB;log.roll.ms: 当前日志分段中消息的最大时间戳与当前系统的时间戳的差值允许的最大范围,默认为168小时;log.index.size.max: 触发偏移量索引文件或时间戳索引文件分段字节限额,默认为10MB;Integer.MAX_VALUE: 追加的消息的偏移量与当前日志分段的偏移量之间的差值大于Integer.MAX_VALUE
参考
1、《深入理解Kafka: 核心设计与实践原理》
2、《Kafka核心源码解读》
3、美团技术团队-Kafka文件存储机制那些事