初识Kafka术语(一)
来看看Kafka的术语都是什么意思吧😄
消息与批次
Kafka的数据单元被称为消息(Record),可以把消息看成是数据库里的一个”数据行”或一条”记录”。消息由字节数组组成,有一个可选的元数据,也就是键,同样也是一个字节数组。
消息可以分批次写入Kafka。批次就是一组消息,这些消息属于同一个主题和分区。如果每一个消息都单独穿行于网络,会导致大量的网络开销,把消息分成批次传输可以减少网络开销,但这也需要在时间延迟和吞吐量之间作权衡: 批次越大,单位时间内处理的消息就越多,单个消息的传输时间就越长。批次数据会被压缩,这样可以提升数据的传输和存储能力,但要作更多的计算。
Topic与Partition
Kafka的消息通过主题(Topic)进行分类,主题可以看作是数据库的表或文件系统的文件夹,可以为每个业务、每个应用甚至每类数据创建专属的主题。
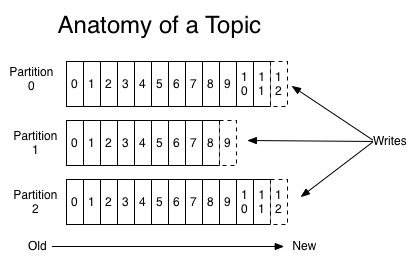
Kafka中的分区机制指的是将每个主题划分成若干个分区(Partition),每个分区是一组有序的消息日志。消息以追加的方式写入分区,然后以先入先出的顺序取出。由于一个主题一般会包含几个分区,因此无法在整个主题范围内保证消息的顺序,但可以保证消息在单个分区内的顺序,生产者生产的每条消息只会被发送到一个分区中,也就是说如果向一个双分区的主题发送一条消息,这条消息要么在分区0中,要么在分区1中。Kafka的分区编号是从0开始的,如果Topic有100个分区,那么它们的分区号就是从0到99。
Producer与Consumer
Kafka的客户端就是Kafka系统的用户,被分为两种基本类型:生产者(Producer)和消费者(Consumer)。
生产者创建消息。一般情况下,一个消息会被发布到一个特定的主题上。生产者在默认情况下把消息均衡地分布到主题的所有分区上,而并不关心特定消息会被写到哪个分区。
不过,通过消息键和分区器可以实现将消息直接写到指定的分区,分区器为键生成一个散列值,并将其映射到指定的分区上。这样可以保证包含同一个键的消息会被写到同一个分区上。也可以使用自定义的分区器,根据不同的业务规则将消息映射到分区。
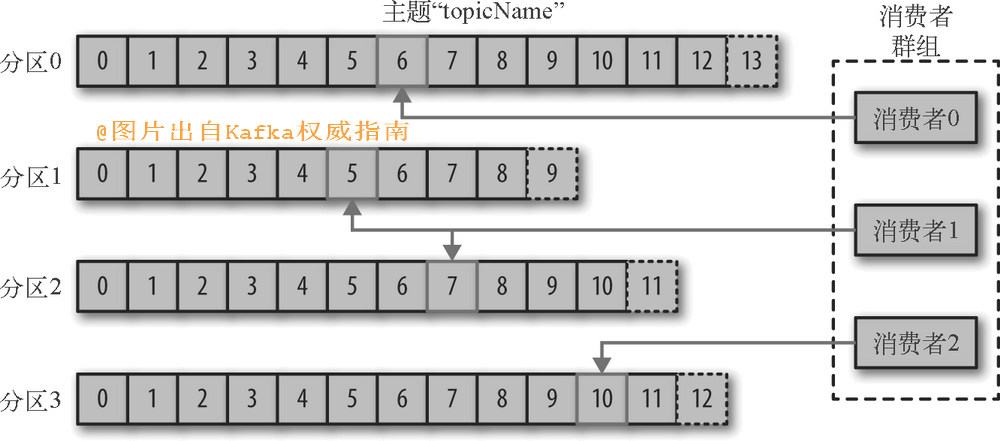
消费者读取消息。消费者订阅一个或多个主题,并按照消息生成的顺序读取它们。消费者通过检查消息的偏移量(Offset)来区分已经读取过的消息。偏移量是另一种元数据,它是一个不断递增的整数值,在创建消息时,Kafka会把它添加到消息里。在给定的分区里,每个消息的偏移量都是唯一的。消费者把每个分区最后读取的消息偏移量保存在Zookeeper或Kafka上,如果消费者关闭或重启,它的读取状态不会丢失。
消费者是消费者群组的一部分,也就是说,会有一个或多个消费者共同读取一个主题。群组保证每个分区只能被一个消费者使用。消费者与分区之间的映射通常被称为消费者对分区的所有权关系。
Broker
Kafka的服务器端由被称为Broker的服务进程构成,即一个Kafka集群由多个Broker组成,Broker接收来自生产者的消息,为消息设置偏移量,并提交消息到磁盘保存。broker为消费者提供服务,对读取分区的请求作出响应,返回已经提交到磁盘上的消息。
接下来仍然是在单机中进行操作,看看启动多个Broker是什么样的:
1 | cp config/server.properties config/server-1.properties |
在server-1.properties和server-2.properties中分别修改如下几个字段:
1 | config/server-1.properties: |
分别启动两个Broker:
1 | $ bin/kafka-server-start.sh config/server-1.properties |
创建一个新的Topic并查看Topic信息:
1 | $ bin/kafka-topics.sh --create --bootstrap-server localhost:9092 --replication-factor 3 --partitions 1 --topic my-replicated-topic |
更常见的做法是将不同的Broker分散运行在不同的机器上,这样如果集群中某一台机器宕机,即使在它上面运行的所有Broker进程都挂掉了,其他机器上的Broker也依然能够对外提供服务。这其实就是Kafka提供高可用的手段之一。
Replica
Kafka中同一条消息能够被拷贝到多个地方以提供数据冗余,这些地方就是所谓的副本(Replica)。Kafka中定义了两类副本:领导者副本(Leader Replica)和追随者副本(Follower Replica),前者对外提供服务,这里的对外指的是与客户端程序进行交互;而后者只是被动地追随领导者副本而已,不能与外界进行交互。副本是在分区层级下的,即每个分区可配置多个副本实现高可用。
Rebalance
Rebalance(重平衡)是说消费者组内某个消费者实例挂掉后,其他消费者实例自动重新分配订阅主题分区的过程。
参考
1、http://kafka.apache.org/intro
2、http://kafka.apache.org/quickstart
3、Kafka权威指南
4、Kafka核心技术与实战