ARTS-week40
Algorithms
1 | class Solution { |
1 | class Solution { |
Review
本周阅读英文文章 Intro to C++: Managing Arrays & Strings
Technique
《计算机网络》网络层流量整形、包调度
流量整形(traffic shaping)是指调节进入网络的数据流的平均速率和突发性所采用的技术。它的目标是允许应用程序发送适合他们需求的各种各样流量,包括带有某种程度的突发,但是要有一个简单而有用的方式向网络描述可能的流量模式。当一个流建立时,用户和网络提供者就该流的流量模式达成一致协议。
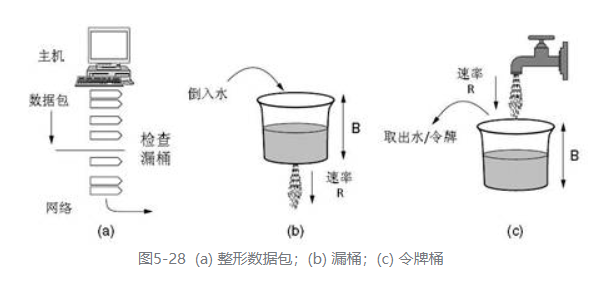
漏桶算法(leaky bucket algorithm):
请想象这样一个桶,它的底部有一个小洞,如图b所示,无论流入漏桶的水的速率多大,只要漏桶中还有水,那么水流出桶的速率是个恒定速率R;如果桶内没有水,则流出桶的速率降为0。此外,一旦桶内的水达到桶的容量B,任何额外进入桶的水都会沿着桶侧分流,最终流失。漏桶可以应用到注入网络的数据包上,对其进行整形和监管,如图a所示。概念上,每个主机在连接到网络的接口中包含一个漏桶。为了向网络发送数据包,必须有可能往漏桶中灌入更多的水。如果漏桶满时来了一个数据包,那么该数据包必须排入队列等漏桶空出来时再接纳,或者被丢弃。前一种策略作为操作系统的一部分可用在对主机进入网络的流量实施整形;后一种策略可用在服务提供商的网络接口,通过硬件对进入网络的流量实施监管。令牌桶算法(token bucket algorithm):
如图c所示,把网络接口想象成一个漏桶,正在往里灌水水龙头速率为R,水桶容量为B。为了发送一个数据包,我们必须能够从桶内掏出水或令牌,俗称为内容(而不是往桶内注水)。桶内只可累积固定数量的令牌,即B,不可能有更多的令牌;如果桶是空的,我们必须等更多的令牌到达才能发送另一个数据包。
在同一个流的数据包之前以及竞争流之间分配路由器资源的算法称为数据包调度算法(packet scheduling algorithms)。不同的流可以预约的潜在资源有以下三种:
1)带宽;
2)缓冲区;
3)CPU周期。
数据包调度算法:
1)FIFO算法,先入先出,在队列满时会丢弃新到的数据包,即尾丢包。
2)由Nagle提出的公平队列算法,针对每条输出线路,路由器为每个流设置单独的队列。当线路空闲时,路由器循环扫描各个队列,然后坐下一个队列中取出第一个数据包发送。以该方式,如果某条输出线路被n个主机竞争,则每发送n个数据包中每个主机获得发送一个数据包的机会。但该算法的缺点是,每个主机的优先级相同。修改过后的算法称为加权公平队列(WFQ,Weighted Fair Queueing),算法复杂度O(logN)。使用赤字循环(deficit round robin)的近似算法针对每个数据包只有O(1)次操作。
Share
使用filecmp比较系统上的文件和目录:
https://pymotw.com/3/filecmp/index.html